

Becommerce.es
Blog personal sobre tecnología, desarrollo y lifestyle. Explorando el mundo del código, servidores y más allá.

Qué es una PWA y cómo funciona (explicado en cristiano)
Las siglas PWA (Progressive Web App) suenan a tecnología complicada, y muchos artículos no ayudan: te sueltan un párrafo lleno de jerga y te quedas igual. Acabo de convertir una...
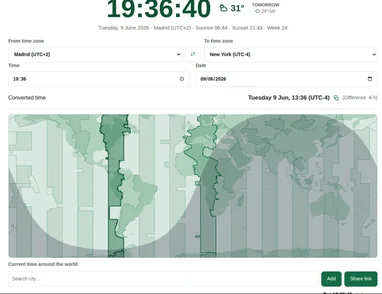
Cómo coordino reuniones entre zonas horarias sin liarme (y la calculadora que uso)
Si trabajas con gente en otros países, conoces el baile: “¿las 3 de la tarde tuyas o las mías?”, “espera, ¿ahí ya habéis cambiado la hora?”, y el clásico de...
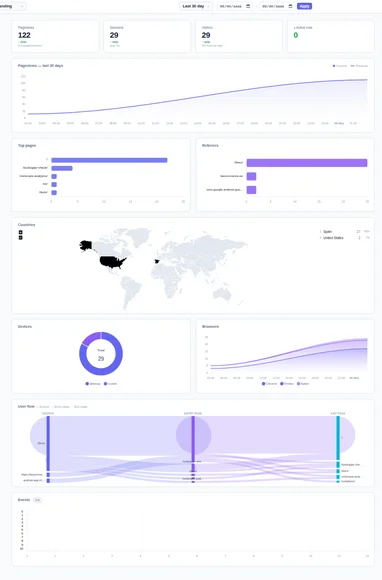
Analíticas Simples y Privadas: Descubriendo Logly.uk
Acabo de instalar un nuevo sistema de analíticas en el blog y estoy realmente impresionado. Se trata de Logly.uk, una alternativa a las analíticas tradicionales enfocada completamente en la privacidad,...

Cómo Publicar tu Web Estática en Cloudflare Pages Automáticamente (Para Oscar)
¡Hola de nuevo, Oscar! En el artículo anterior vimos los conceptos básicos de Git y cómo guardar tu proyecto en un repositorio privado de GitHub. Ahora que ya tienes tu...
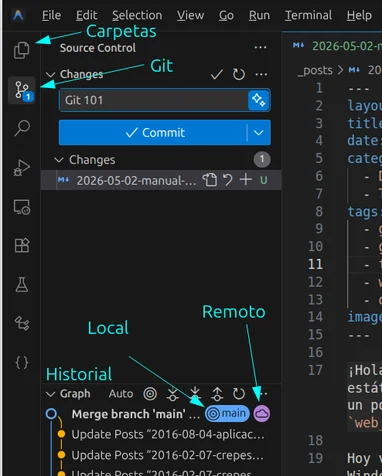
Manual Básico de Introducción a Git (Para Oscar)
¡Hola Oscar! Sé que manejas Excel a la perfección y que también llevas alguna que otra página web estática. Sin embargo, a medida que los proyectos crecen, gestionar los archivos...
Cómo he implementado SimpleSupport.uk en mi web como widget de soporte y contacto
Hace poco decidí mejorar la forma en la que gestiono el soporte y las dudas de los usuarios en la web. Tras analizar varias opciones, me decanté por implementar SimpleSupport.uk,...
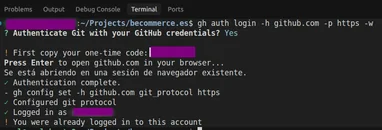
Cómo recuperar el acceso a tu repositorio de GitHub desde la terminal fácilmente
A todos nos ha pasado: estás en medio de un flujo de trabajo espectacular, haces tu commit, te dispones a hacer un git push a tu repositorio privado y, de...

Tailscale: El superpoder invisible para la infraestructura de tu E-Commerce
En el mundo del comercio electrónico (y de Becommerce en particular), la seguridad ya no es una opción, es la base de todo. Ya sea que estés gestionando bases de...

Arquitectura para un CMS Gratuito en Cloudflare (Estilo WordPress)
¿Te imaginas tener tu propio CMS (sistema de gestión de contenidos) parecido a WordPress, pero sin tener que pagar absolutamente nada por alojamiento web mensual, y además con una velocidad...

Seguridad desde el Diseño: El doble filo de los frameworks minimalistas
Cuando hablamos de Seguridad desde el Diseño (Security by Design), nos referimos a la práctica fundamental de integrar la seguridad en la arquitectura de nuestra aplicación desde el primer boceto,...

Factura Electrónica y VeriFactu en España: La Guía Definitiva (2026)
Si gestionas un negocio o eres autónomo en España, llevas años oyendo hablar de la Ley Crea y Crece y la temida “Factura Electrónica Obligatoria”.

El laberinto de las redirecciones en Cloudflare Pages y Jekyll: Solución definitiva
Al migrar un blog a Cloudflare Pages con un generador de sitios estáticos como Jekyll, uno de los primeros retos técnicos es la gestión de las redirecciones. Parece sencillo sobre...

Depurando Race Conditions: Cuando DOMContentLoaded Falla
A veces, las mejoras de rendimiento traen efectos secundarios inesperados. Recientemente, al migrar Becommerce.es a una infraestructura más rápida, una funcionalidad crítica dejó de funcionar: el buscador.
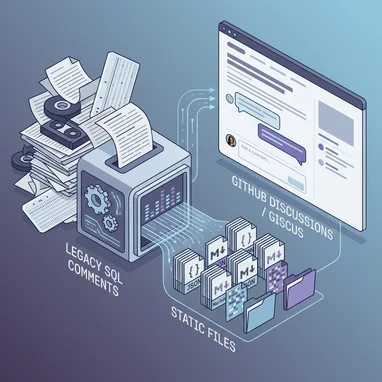
La Guía Definitiva: Comentarios en Jekyll y Migración Híbrida con Giscus
Una de las grandes “pérdidas” al migrar de WordPress a un sitio estático como Jekyll es el sistema de comentarios. Al no tener base de datos, no podemos simplemente hacer...
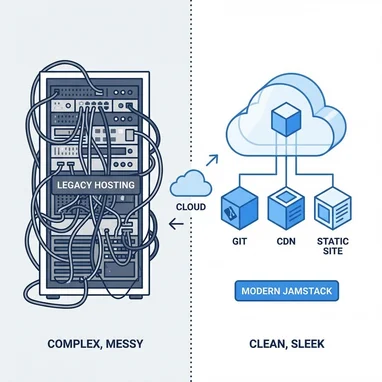
De WordPress y VPS a Sitio Estático: Mantenimiento Cero y Paz Mental
Durante años mantuve este blog (y otros proyectos) en un servidor VPS propio con Ubuntu y WordPress. Si has administrado servidores, sabes lo que eso significa: una constante lucha contra...

Docker Swarm contenedor php-fpm infectado 100% CPU
Cómo Arreglar Docker Swarm Infectado con Malware PHP-FPM

Receta de dumplings polacos rellenos de carne picada, Pyzy
¡Prepara unos deliciosos Pyzy polacos!

No se puede montar DATOS, Ubuntu 24.04, Error mounting /dev/sdc1 at /media/raul/DATOS1: mount(2) system call failed: No such file or directory
No puedo montar mi unidad DATOS en Ubuntu 24.04